Aquest article em serveix de pràctica i de proves per al curs "Del dato al relato" oferit pel departament de Formació de la Diputació de Castelló i impartit per l'expert en ciència i tecnologia Javier Cantón que ens està donants continguts sobre anàlisi de dades, neteja de fitxers i bases de dades, i visualització de gràfics de temàtica diversa com Big Data, Smart Data, Small Data, el principi ETL (de l'anglès "Extract, Transform and Load") que vindria a ser "extaure, transformar i carregar", etc.
També en aquest curs "Del dato al relato" estem aprenent la importància de la presentació a l'hora de generar un relat, una comunicació, una informació que represente bé allò que volem comunicar, i hem anat veient des de conceptes biològics, veiem amb el cervell i els ulls són nomès el nostre instrument òptic de captació de la llum, fins a conceptes psicològics, la percepció de cada persona pot ser distinta per qüestions d'edat, cultura, etc, per tant cal ser el més clars i directes que puguem per a comunicar bé allò que realment volem.
De moment, estem treballant amb el següent programari:
- Table Capture (extensió navegador Google Chrome)
- Table Capture (extensió navegador Mozilla Firefox)
- Web Scraper (extensió navegador Google Chrome)
- Web Scraper (extensió navegador Mozilla Firefox)
- Wordclouds
- Wordart
- Tabula
- LibreOffice
- Tableau (versió web)
- Flourish
- Rawgraphs
- OpenRefine
- Desgrabador
- Cosmograph.app
- Gephi
- Microsoft Power BI
- Grafana
- VOSviewer
- Citnetexplorer
- NodeXL
- Datawrapper
OBJECTIU
Amb aquest senzill i xicotet exemple de Dataset que veuràs a continuació vull simplement practicar conceptes apresos al curs, provar certs tipus de gràfics i visualitzacions, provar un poc les configuracions i personalitzacions i conèixer més coses per a quan haja de fer-ho a grans Datasets.
EXPLICACIÓ DE L'EXPERIMENT
Aleshores, la idea que he fet ha segut descarregar uns videos del expresident de la Diputació de Castelló, Javier Moliner, i l'actual president Pepe Martí, i comparar un poc el seu missatge global.
En aquest article faig una prova un poc "avançada" amb dades, i dic "avançada" perquè realment partiré d'una font multimèdia per a explotar dades, és a dir, de videos de Youtube. I com extrauré informació dels videos, podràs pensar? Doncs amb la utilitat videogrep podem descarregar transcripcions automàtiques i extraure text dels videos, així com tallar videos a partir de les paraules o frases que vullguem, una xulada que vaig aprendre fa poc, però que volia practicar per a aprendre un poquet més.
RESULTATS NO VINCULANTS EN CAP SENTIT NI DIRECCIÓ
Realment, aquest experiment no és una comparació vinculant per a ares, ja que he agafat vídeos aleatoris que m'han semblant nets (sense massa soroll de fons) i on apareixen, principalment, els actors principals que vull analitzar.
Si realment vullguèrem fer un estudi o un anàlisi polític o periodístic, caldria situar als dos actors en la mateixa situació i context: per exemple un míting polític durant les mateixes eleccions, un debat sobre canvi climàtic on participen els dos, una compareixença a televisió sobre una notícia concreta, etc.
OBTENCIÓ DE LES DADES (VÍDEOS DE YOUTUBE)
Una vegada ja sabem els vídeos que volem analitzar, els dscarregarem individualment amb yt-dlp. També podem descarregar molts vídeos al vol, per exemple tots els vídeos d'un canal de youtube o els vídeos de resultats d'una cerca a Youtube, però això tardarà un poc de temps:
Per exemple:
yt-dlp https://www.youtube.com/watch?v=9a78vy1ytUM --sub-langs 'es.*' --write-auto-subs
EXTRACCIÓ DE LES DADES
Una vegada ja tenim les transcripcions, extrareum les paraules (individuals o frases) més utilitzades en els videos de cada personatge amb la següent ordre:
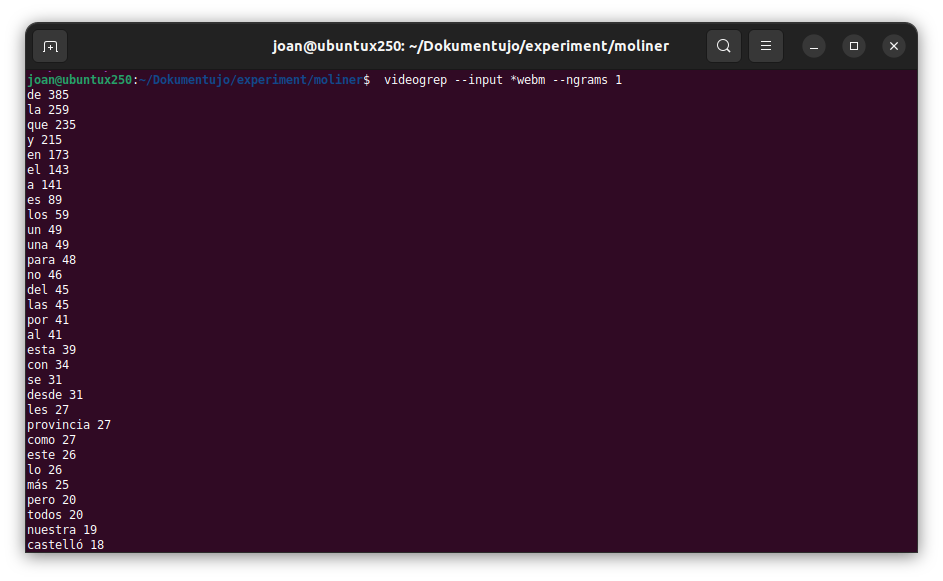
videogrep --input *webm --ngrams 1
I obtindrem un resultat així, on apareixen les paraules (moltes vegades monosílabs) i al costat un número:
Les obrirem amb LibreOffice i les guardarem com a CSV/TSV.
RESULTATS DE L'EXTRACCIÓ I VISUALITZACIÓ
Ací, a continuació, mostraré en dues columnes els resultats d'aquest experiment on analitze les paraules pronunciades al conjunt de vídeos per a fer proves d'extracció, neteja de dades i visualització.

Agafem aquestos sis vídeos originals en Youtube:
Video 1
Video 2
Video 3
Video 4
Video 5
Video 6
PARAULES MÉS UTILITZADES ALS SEUS VÍDEOS
Extraem la transcripció en castellà i/o valencià i::
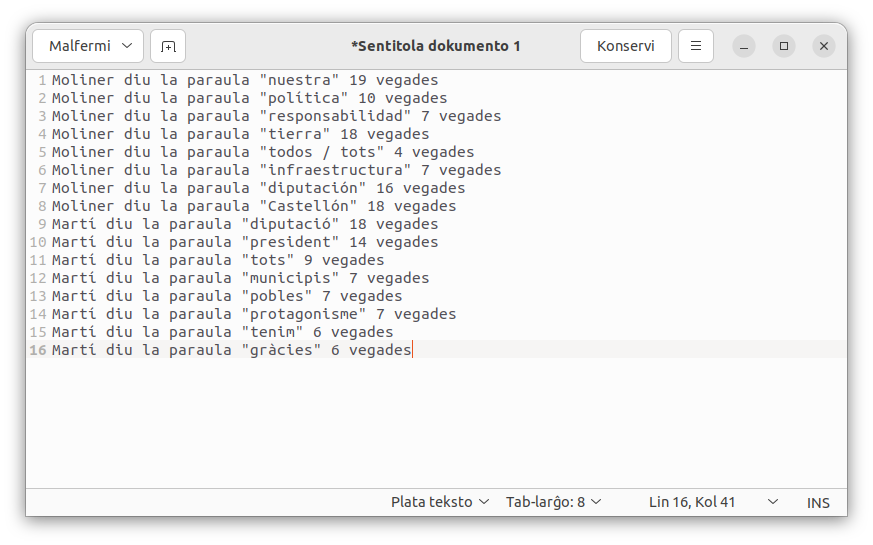
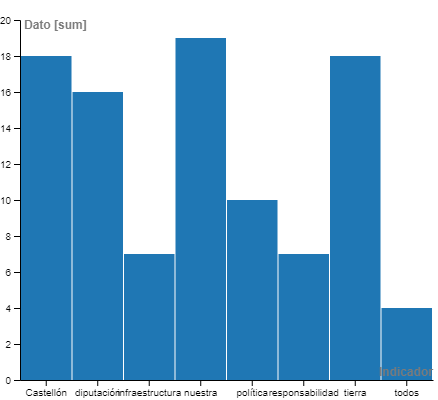
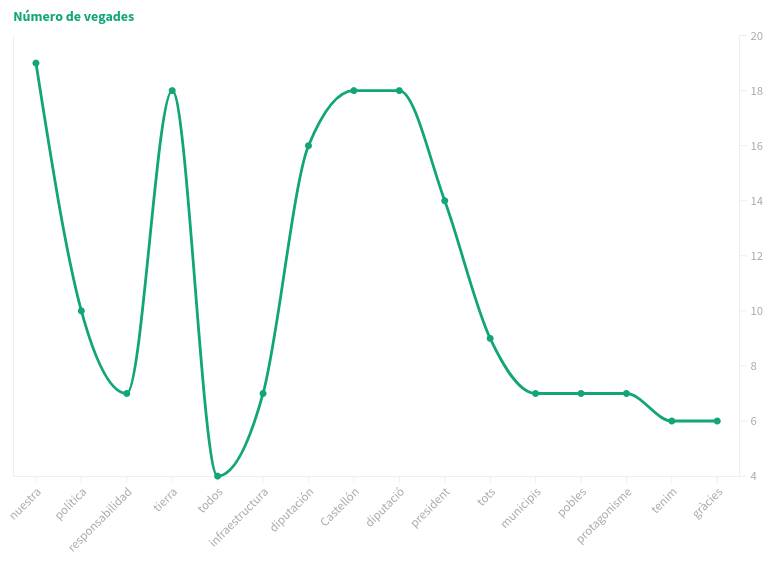
Moliner diu la paraula "nuestra" 19 vegades
Moliner diu la paraula "política" 10 vegades
Moliner diu la paraula "responsabilidad" 7 vegades
Moliner diu la paraula "tierra" 18 vegades
Moliner diu la paraula "todos / tots" 4 vegades
Moliner diu la paraula "infraestructura" 7 vegades
Moliner diu la paraula "diputación" 16 vegades
Moliner diu la paraula "Castellón" 18 vegades
Paraules més repetides a la transcripció automática:
- moliner-CSV-complet-1.csv_.zip
- moliner-CSV-complet-2.csv_.zip

Agafem aquestos sis vídeos originals en Youtube:
Video 1
Video 2
Video 3
Video 4
Video 5
Video 6
PARAULES MÉS UTILITZADES ALS SEUS VÍDEOS
Extraem la transcripció en castellà i/o valencià i::
Martí diu la paraula "diputació" 18 vegades
Martí diu la paraula "president" 14 vegades
Martí diu la paraula "tots" 9 vegades
Martí diu la paraula "municipis" 7 vegades
Martí diu la paraula "pobles" 7 vegades
Martí diu la paraula "protagonisme" 7 vegades
Martí diu la paraula "tenim" 6 vegades
Martí diu la paraula "gràcies" 6 vegades
Paraules més repetides a la transcripció automática:
- pepe-marti-CSV-complet-1.csv_.zip
- pepe-marti-CSV-complet-2.csv_.zip
Ara que ja tenim la informació, ajuntarem el resultat de les paraules més utilitzades pels dos actors principals d'aquest experiment i ho deixarem en un fitxer amb format de text pla. En el meu cas, jo ho faig amb Gedit:
Ara, a continuació obrim el fitxer que tenim en text pla i el transformem separat per espais per tal de que ens quede cada paraula en una columna del full de càlcul. Ho farem de la següent manera:
I el resultat que obtindrem serà una cosa així, on veurem que cada paraula està efectivament en una columna:
Ara netejarem les dades esborrant totes aquelles columnes que no ens interesen, i finalment obtindrem un format així:
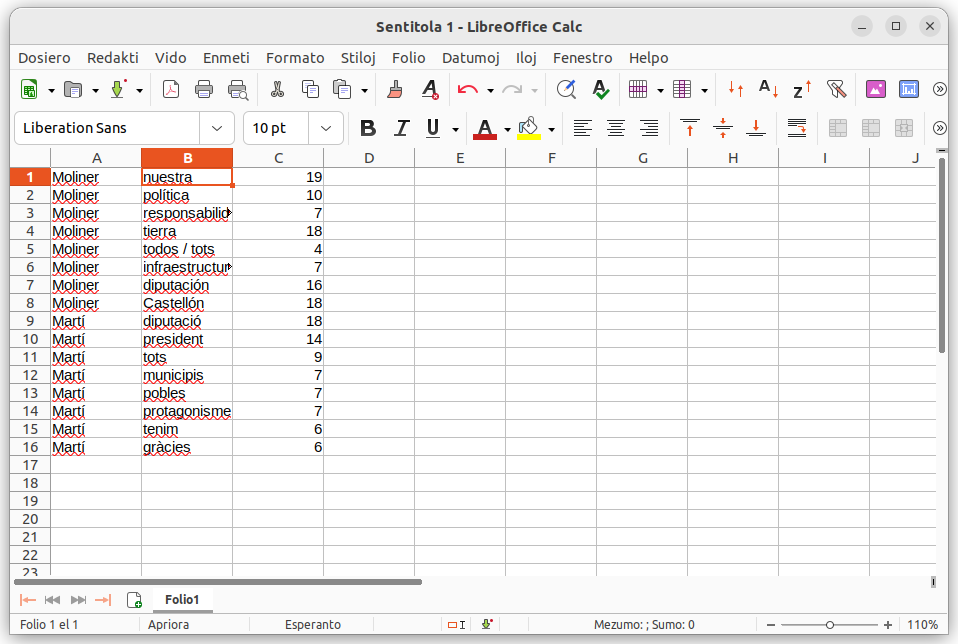
Ja tenim el nostre CSV final amb els resultats que jo volia extreure, que són 8 paraules per cada actor, és dir un total de 16 paraules.
Núvols d'etiquetes:

I ací un amb un poc de color:

Ací un gràfic de barres clàssic:
Núvols d'etiquetes:

I ací un amb un poc de color:

Ací un gràfic de barres clàssic:
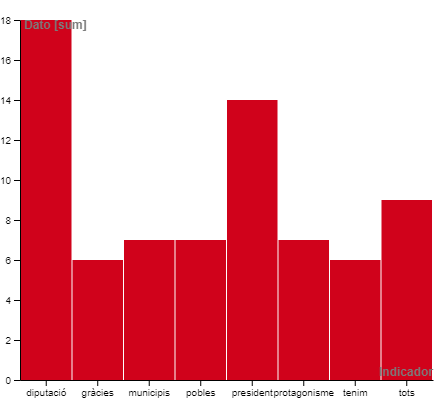
Ací un gràfic de barres amb múltiple selecció i series:
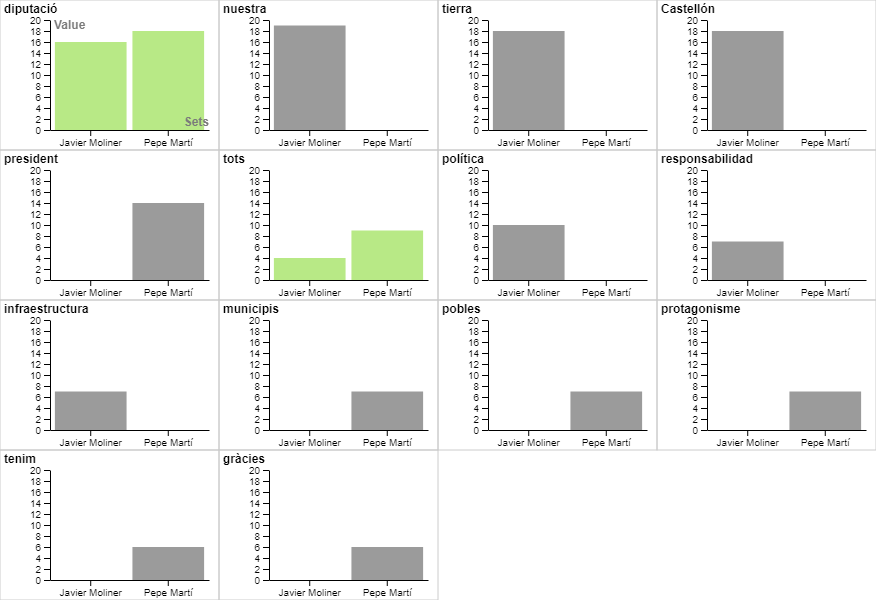
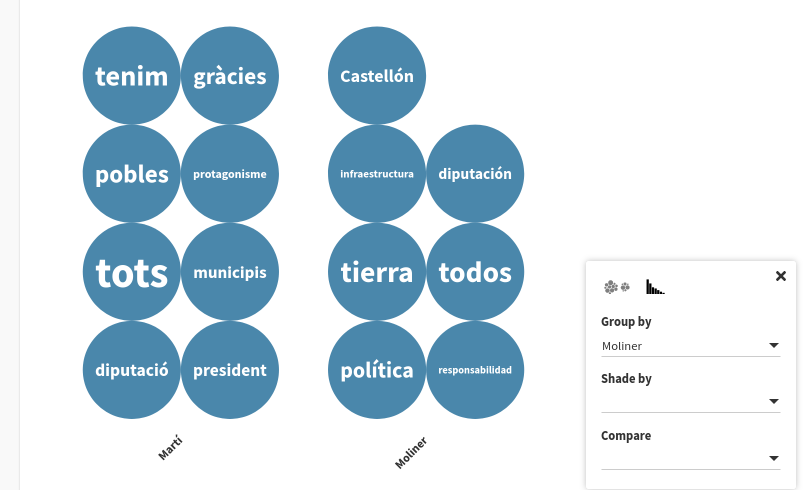
Ací un gràfic de tipus "Circle packing":

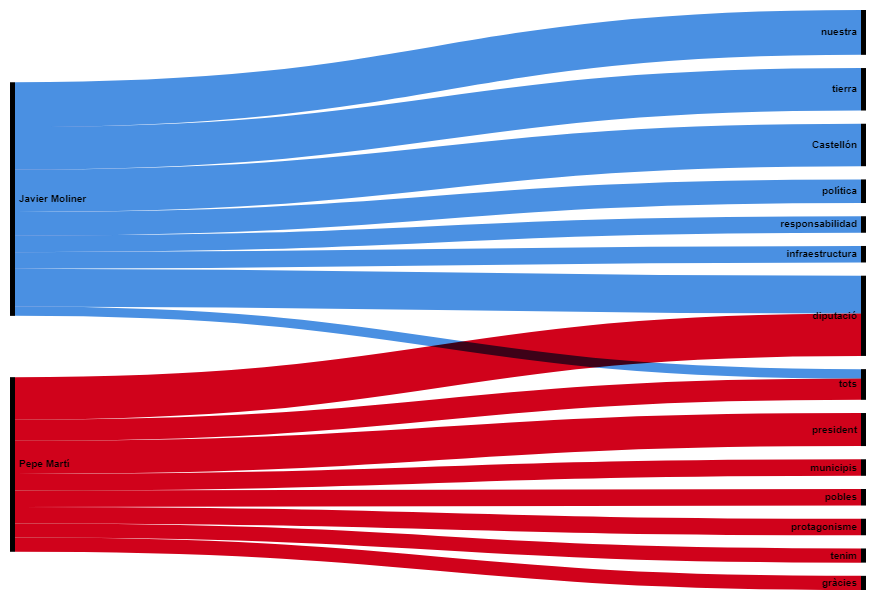
Ací un diagrama de tipus "Sankey diagram":
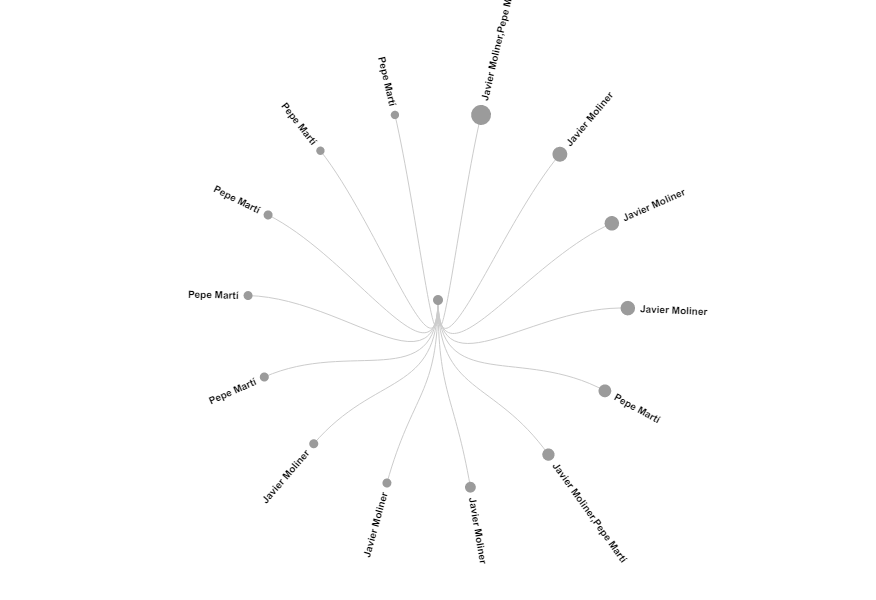
Ací un diagrama de tipus "circular dendogram". El professor va comentar que aquest tipus de gràfic no s'enten massa bé d'aquesta manera amb colors grisos. Tal vegada no ha segut adequat per aquest tipus de Dataset:
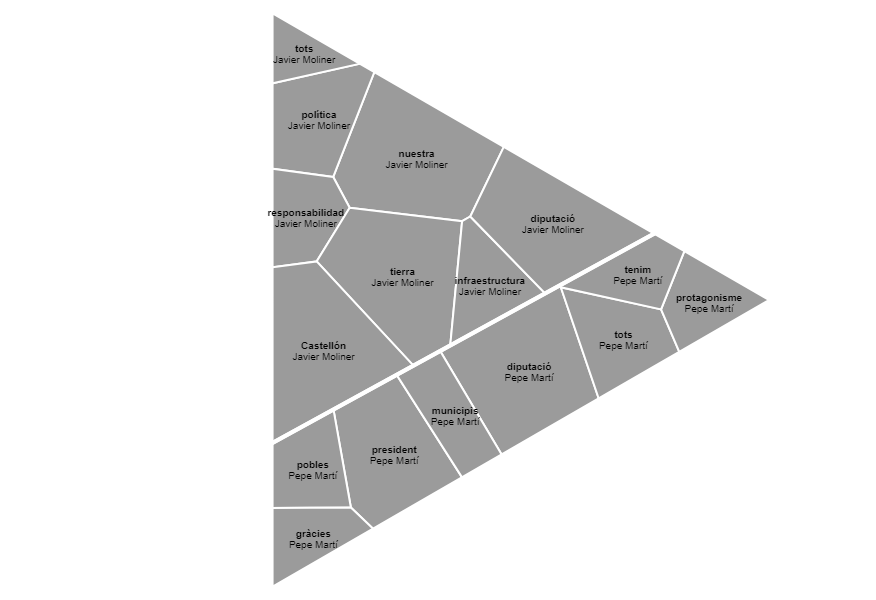
Ací un mapa d'arbre de tipus "voronoi treemap". El professor va dir que no tindria massa sentit aquest tipus de diagrama, però de totes maneres (al igual que el gràfic següent que veurem a continuació) seria millor configurar-ho per colors o tontalitats d'un mateix color, per a poder distinguir bé les variables grans i les menudes:
Ací un diagrama de tipus "treemap". El professor va comentar que aquest tipus de diagrama o gràfic seria millor amb colors, ja que ara mateix no es pot analitzar ben bé les variables i dades que estem agfant del Dataset, però la idea és interessant:

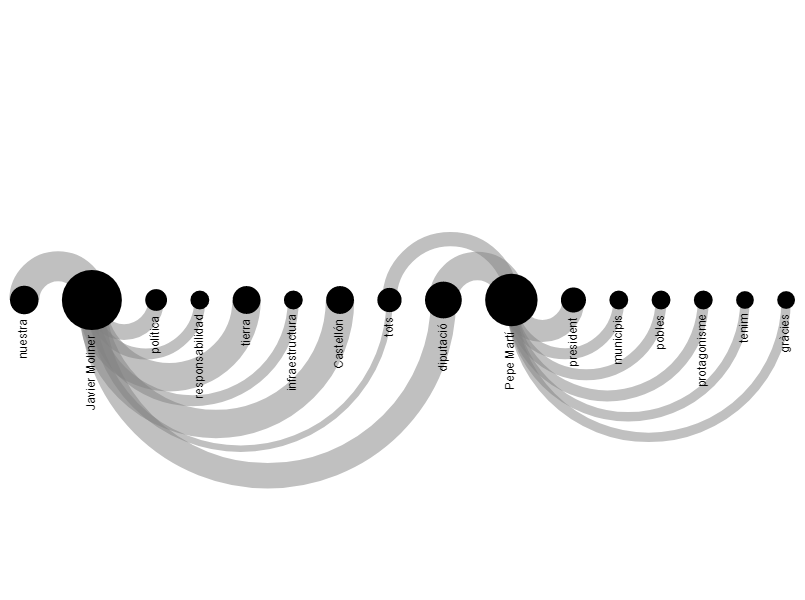
Ací un diagrama de tipus "arc diagam":
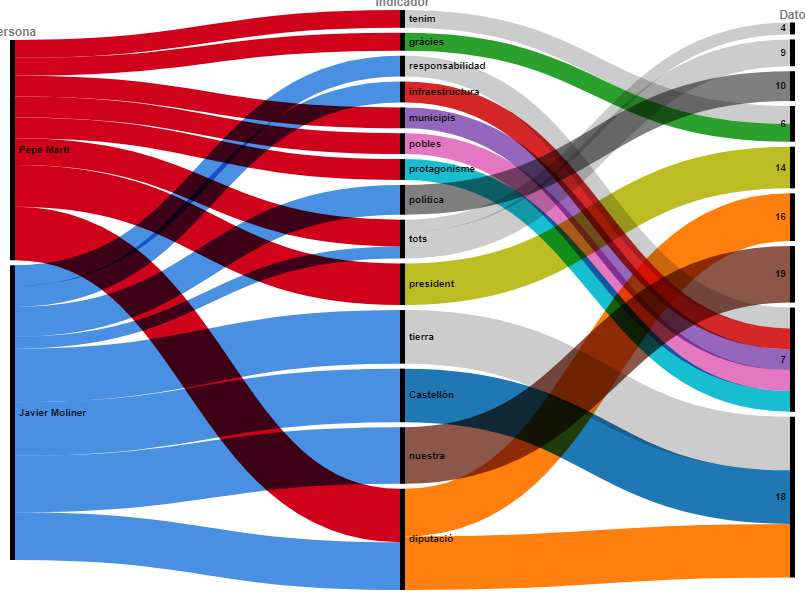
Ací un diagrama de tipus "alluvial diagram":
Ací una visualització de tipo "survey" a Flourish. Al professor li va semblar bé. Tal vegada es podria configurar amb colors i, segons el número d'importància de la variable que estem representant, que siga un color o un altre color:
Ací un gràfic d'àrea fixe. No es recomanaria mostrar aquest tipus de gràfica per a repeticions de paraules, ja que l'objectiu d'aqeust tipus de gràfica seria mostrar aument i disminució d'una varaible (diners, velocitat, metres, població, etc) i no repeticions de números de variables, com és el cas d'aquest Dataset:
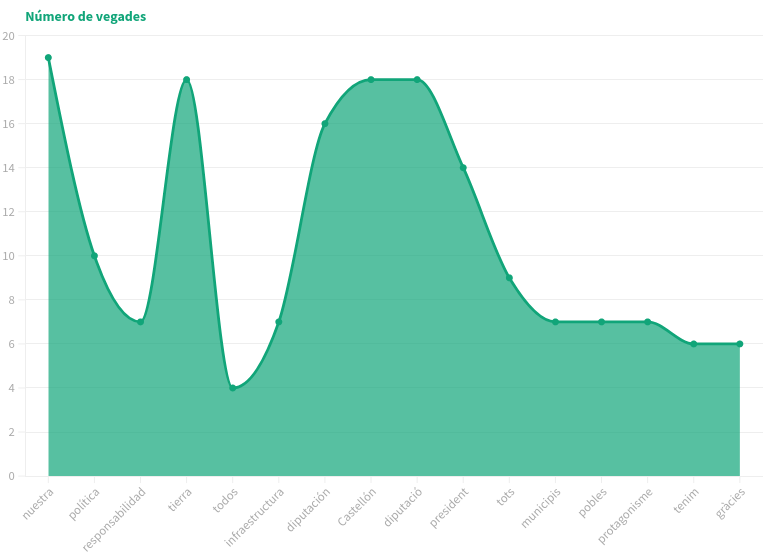
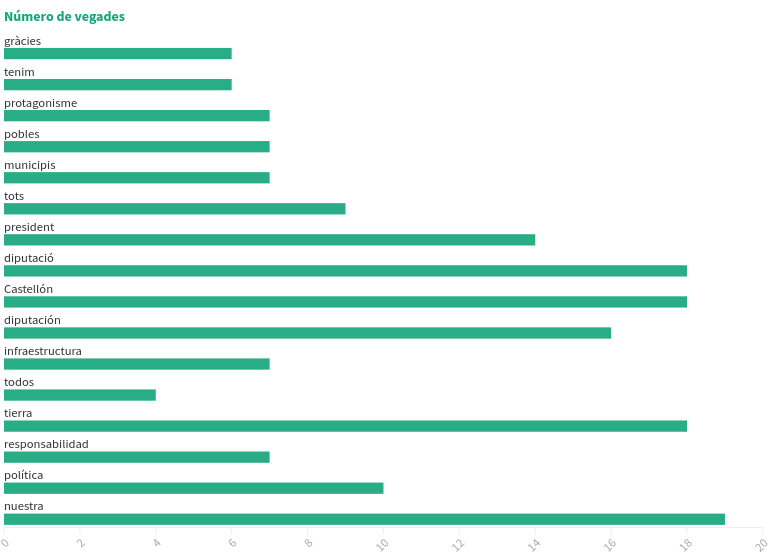
Ací un gràfic de barres agrupat. Al professor li va semblar bé al mostrar les barres dels resultats així com les etiquetes (les paraules) de manera horitzontal perquè es poden llegir molt fàcilment:
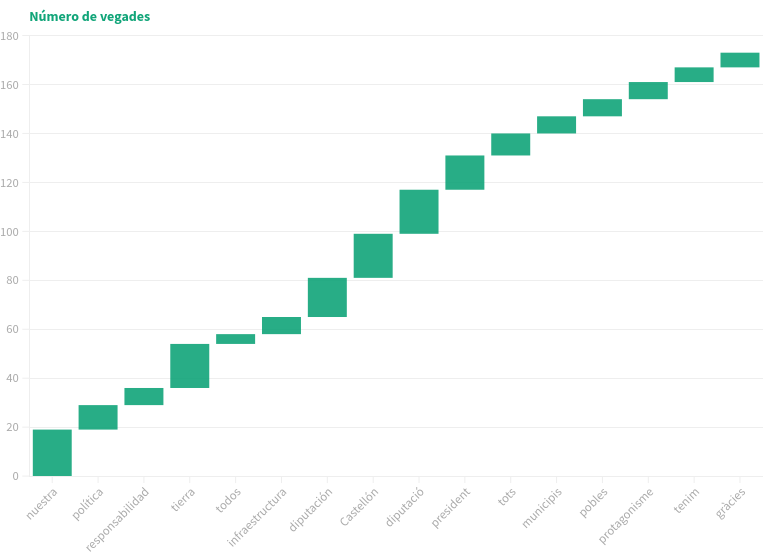
Ací un gràfic de columnes en cascada. Al professor li va semblar bé:
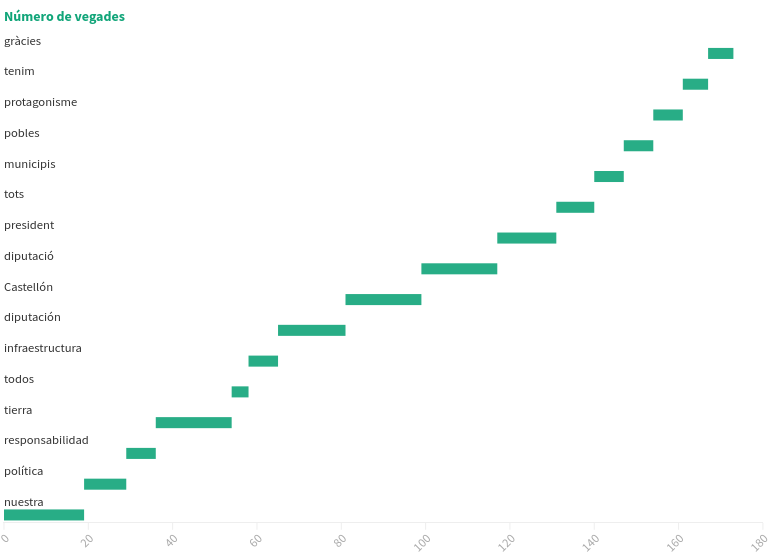
Ací un gràfic de barres en cascada. Al professor li va semblar bé:
Ací un gràfic combo de linies i columnes. Al professor li va semblar bé:
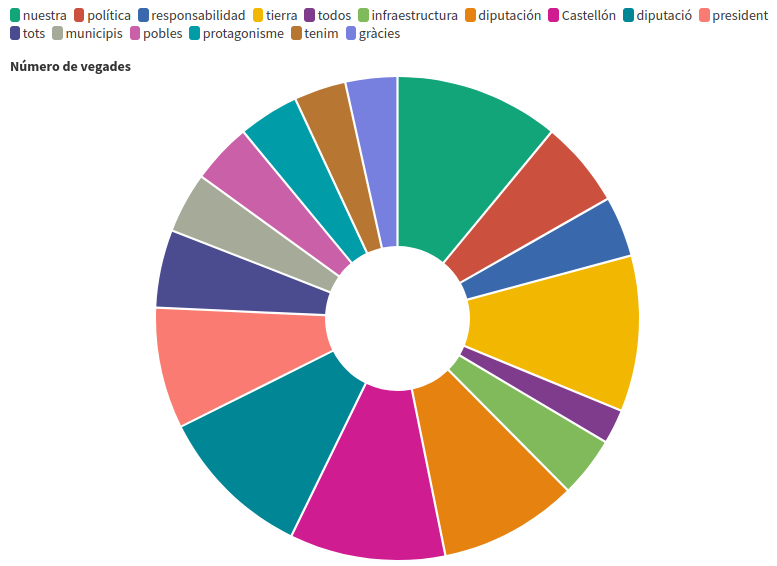
Ací un gràfic de tarta/donut amb tots els valors. El professor va explicar que realment no hem de crear aquest tipus de gràfic de tarta quan hi haja més de sis opcions perquè ni és fàcil analitzar les dades, ni és fàcil comunicar bé allò que volem mostrar i pot dur a errors perquè alguns colors es poden repetir. Aquest és un exemple que vaig fer: